| Linuxové noviny | 07-08/2001 | ||
|
| |||
Definice RAIDuNa rozdíl od jiných hardwarových problémů jsou výpadky disků obvykle spojeny s časově náročnou obnovou dat ze záloh. Těmto problémům se ale můžeme vyhnout použitím redundantních diskových polí RAID, která jsou vůči výpadkům jednotlivých disků odolnější. Označení RAID pochází z anglického "Redundant Array of Inexpensive Disks" nebo také "Redundant Array of Independent Disks". Jedná se tedy o několik disků sloučených do jednoho logického svazku, který zpravidla zajišťuje určitou redundanci dat, díky které je pak odolný vůči hardwarovým výpadkům některého z disků. I když je v názvu obsaženo slovíčko "redundant", ne všechny typy RAIDu jsou skutečně redundantní. Zatímco některé typy RAIDu jsou navrženy s ohledem na maximální bezpečnost dat, jiné jsou naopak optimalizovány na rychlost.
Hardwarové a softwarové implementace RAIDuRAID lze provozovat v podstatě dvojím způsobem. Buď je realizován v hardwaru, což obnáší speciální řadič osazený procesorem a zpravidla vybavený vlastní pamětí, která slouží jako cache. Veškeré funkce RAIDu plní řadič a z pohledu operačnímu systému se chová jako jediný disk. Tato řešení bývají poměrně drahá (Mylex, DPT - nyní Adaptec, ICP Vortex, velcí výrobci PC jako HP, IBM, Compaq apod. mají své vlastní implementace). Předností hardwarových řešení bývá maximální spolehlivost a ve srovnání se softwarovou variantou RAIDu dovedou odlehčit zátěži systému. RAID ovšem také může být realizován patřičným ovladačem na úrovni operačního systému a spousta operačních systémů to také dnes umožňuje. Toto řešení může být za jistých okolností flexibilnější a rychlejší, ale také náročnější na systémové prostředky - zejména na čas procesoru. V posledních letech se setkáváme i s napůl hardwarovými/softwarovými implementacemi RAIDu, kdy hardware obsahuje jen minimální podporu a většinu práce dělá ovladač - tato varianta je levná, ale řada produktů této kategorie je nevalné kvality a výkonu. Tento článek je zaměřený na softwarový RAID pod Linuxem.
Teorie fungování RAIDuNež se zaměříme na detaily softwarového RAIDu pod Linuxem, podíváme se na princip fungování jednotlivých typů RAIDu a jejich vlastnosti.
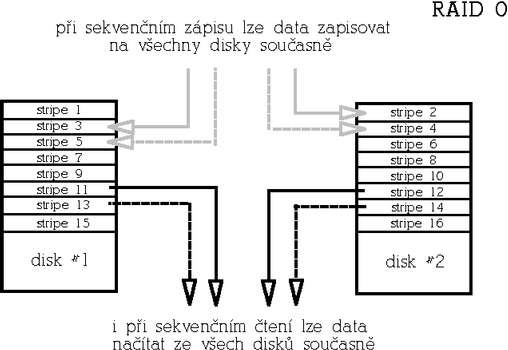
RAID 0 (Nonredundant striped array)Tento typ je určen pro aplikace, které vyžadují maximální rychlost a není redundantní. Naopak je potřeba vzít v úvahu, že pravděpodobnost výpadku takového pole roste s počtem disků. Ideální použití představují audio/video streamingové aplikace, eventuálně databáze a obecně aplikace, při kterých čteme sekvenčně velká množství dat. Základní jednotkou pole je tzv. stripe (z angl. "stripe", česky pruh), což je blok dat určité velikosti (běžně 4-64kB v závislosti na aplikaci). Po sobě jdoucí data jsou pak v poli rozložena střídavě mezi disky do "stripů" takovým způsobem, aby se při sekvenčním čtení/zápisu přistupovalo ke všem diskům současně. Tím je zajištěna maximální rychlost jak při čtení tak i zápisu, ale současně je tím dána také zranitelnost pole. Při výpadku kteréhokoliv disku se stávají data v podstatě nečitelná (respektive nekompletní). RAID 0 bývá označován rovněž jako striping. Protože není redundantní, má nejvýhodnější poměr cena/kapacita. Počet disků je libovolný. Je ovšem třeba pamatovat na to, že s rostoucím počtem disků v poli roste i pravděpodobnost výpadku pole (protože výpadek libovolného disku znamená havárii celého pole); RAID 0 je tedy velmi rychlý, ale méně bezpečný než samostatný disk.
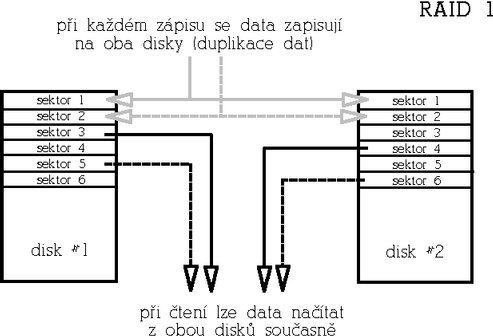
RAID 1 (Mirrored array)RAID 1 je naopak maximálně redundantní. Rychlost čtení může být oproti samostatnému disku výrazně vyšší, rychlost zápisu je stejná jako u samostatného disku. Funguje tak, že data jsou při zápisu "zrcadlena" na všechny disky v poli (tedy v případě RAIDu 1 tvořeného dvěma disku jsou data duplikována apod.). Při čtení lze využít vícero kopií dat a podobně jako u RAIDu 0 číst za všech disků současně. Tento typ pole je určen pro aplikace s důrazem na maximální redundanci. Výhodou tohoto redundantního řešení je stabilní výkon i v případě výpadku disku, nevýhodou je poměr cena/kapacita. Počet disků bývá buď 2 anebo libovolný, čím větší počet disků, tím větší redundance a odolnost proti výpadku.
RAID 2 (Parallel array with ECC)Pole tohoto typu jsou dnes již historií, protože dnešní disky mají vlastní opravné mechanismy a uchovávají ECC informace pro každý sektor samy. V polích tohoto typu se stripovalo po jednotlivých sektorech a část disků pole byla vyhrazena pro ukládání ECC informací. Jakékoliv čtení i zápis proto zpravidla zahrnovalo přístup ke všem diskům pole, což bylo překážkou vyššího výkonu zejména u aplikacích pracujících se většími kusy dat. Tento typ není redundantní.
RAID 3 (Parallel array with parity)Také tento typ polí se již nepoužívá, jedná se o předchůdce RAIDu 4. Stripovalo se po sektorech, ale jeden disk byl vyhrazen jako paritní, což zajišťovalo redundanci (princip zajištění redundance je stejný jako u RAIDu 4 a 5, který je popsán níže). Protože i v tomto případě se stripovalo po sektorech, jakékoliv čtení i zápis zpravidla zahrnovalo přístup ke všem diskům pole.
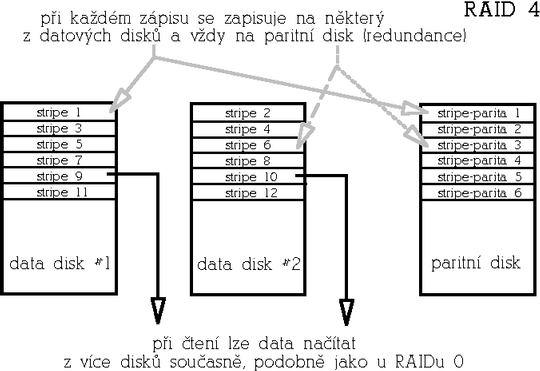
RAID 4 (Striped array with parity)Raid 4 je redundantní pole, které se dnes již používá málo. Funkčně je podobné RAIDu 5, který je ale výkonnější. Funguje tak, že jeden disk je vyhrazen jako tzv. paritní disk. Na paritním disku je zaznamenán kontrolní součet (operace XOR přes data stejné pozice jednotlivých disků). Pokud tedy dojde k výpadku některého z datových disků, lze data rekonstruovat z dat zbylých disků a parity uložené na paritním disku. RAID 4 je odolný vůči výpadku libovolného jednoho disku a má tedy příznivý poměr cena/kapacita. Paritní disk ale představuje úzké hrdlo této architektury při zápisech, protože každý zápis znamená také zápis na paritní disk. Mimimální počet disků je 3.
RAID 5 (Striped array with rotating parity)Tento typ poskytuje redundanci vůči výpadku libovolného jednoho disku s dobrým poměrem cena/kapacita a výkonem. RAID 5 je vylepšená varianta RAIDu 4 v tom, že parita není uložena na jednom vyhrazeném disku, ale je rozmístěna rovnoměrně mezi všemi disky pole, čímž se odstraní úzké hrdlo architektury RAIDu 4.
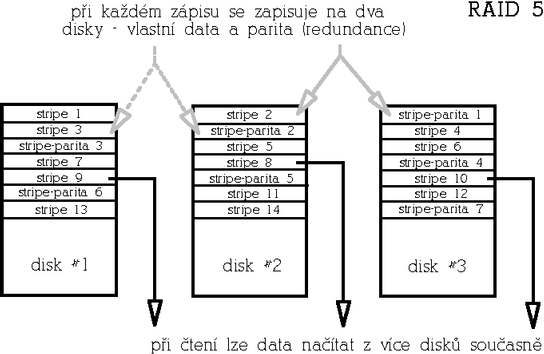 Paritu lze spočítat buď tak, že skutečně načteme a XORujeme data z odpovídajících datových stripů všech disků (takto se parita počítá při inicializaci pole, vyžaduje to tedy přístup ke všem diskům). Ve druhém případě načteme původní data z datového stripu, která se mají změnit, provedeme XOR s novými daty a výsledek ještě XORujeme s původní hodnotou parity (takto se parita počítá na již inicializovaném běžícím poli). Zápis dat tedy představuje dvoje čtení (dat a parity), výpočet parity a dvojí zápis (opět dat a parity). Počet přístupů na disk při zápisu je v tomto případě konstantní bez ohledu na počet disků v poli - přistupuje se vždy ke dvěma diskům - a to také má za následek nižší výkon tohoto typu pole ve srovnání s redundantním RAIDem 1.
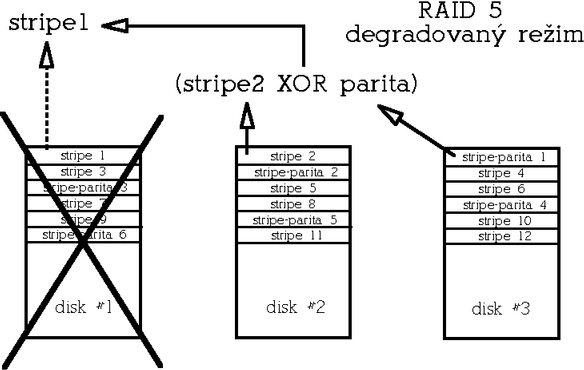
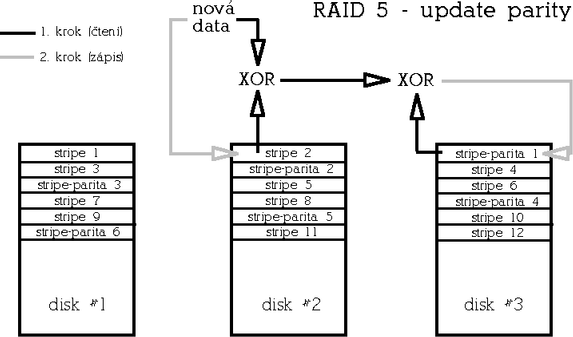 V degradovaném režimu (degradovaný režim znamená stav, kdy je některý z disků z pole vyřazen kvůli hardwarové chybě) se pak musejí data uložená na vadném disku odvodit z dat zbývajících disků a parity. Na rozdíl od redundantního RAIDu 1, kde výpadek disku obvykle neznamená výrazný pokles výkonu, vykazuje RAID 5 v degradovaném režimu výrazně snížený výkon zejména při čtení. Minimální počet disků pro tento typ diskového pole jsou 3.
Kombinace více typů políZ definic výše popsaných typů polí vyplývá, že redundantní pole nejsou tak rychlá, jak bychom si mohli přát a naopak u RAIDu 0 nám chybí redundance. Existuje ovšem možnost, jak výhody jednotlivých typů diskových polí spojit. Tato metoda spočívá ve vytvoření kombinovaných polí, kdy disky v poli určitého typu jsou samy tvořeny poli jiného typu. Příkladem může být např. RAID 1+0, kdy jsou pole typu RAID 1 dále sloučeny do RAIDu 0. Takové pole je pak redundantní (toleruje výpadek až dvou disků), rychlejší zejména v zápisech než samotný RAID 1, a má lepší poměr cena/kapacita než RAID 1 (velikost je zde n/2 * disk a minimální počet disků je pak 4. Další možností je třeba RAID 0+1, RAID 5+0, RAID 5+1 apod.
Jak RAID ošetří výpadek diskuVšechny typy redundantních polí obvykle umožňují nakonfigurovat kromě aktivních disků ještě 1 či více rezervních disků. Aktivními disky zde rozumíme disky, které jsou součástí funkčního pole. V případě výpadku některého z aktivních disků pak může systém místo vadného disku okamžitě začít používat disk rezervní. Po aktivaci rezervního disku do pole systém provede na pozadí (tedy bez narušení dostupnosti pole) rekonstrukci pole a jakmile je rekonstrukce hotova, je pole opět plně redundantní. Rekonstrukcí je míněna buď synchronizace obsahu nového disku s ostatními aktivními disky (v prípadě RAIDu 1), anebo rekonstrukce obsahu původního vadného disku na základě redundantní informace (jedná-li se o RAID 4 nebo 5). Po dobu, než rekonstrukce proběhne, se pole nachází v tzv. degradovaném režimu, kdy v závislosti na konfiguraci nemusí být redundantní a v případě RAIDu 5 se to projeví sníženým výkonem (odtud název "degradovaný režim"). Je samozřejmě možné pole provozovat bez rezervních disků a disk vyměnit později manuálně. Detailně se na výměnu disků a rekonstrukci polí ještě podíváme později.
Redundantní pole neznamenají konec zálohRedundantní disková pole jsou odolná pouze vůči výpadkům určitého počtu disků. Neochrání před výpadkem napájení, poškozením souborového systému při pádu celého systému nebo chybou administrátora. Proto je potřeba myslet i na další metody ochrany dat - např. na záložní zdroje napájení (UPS), žurnálovací souborové systémy apod. a v každém případě pravidelně zálohovat.
Typy polí podporovaných Linuxovým ovladačem RAIDuAž doposud jsme se zabývali pouze teorií fungování diskových polí, podívejme se tedy jak to vypadá se softwarovým RAIDem v Linuxu. Softwarová implementace RAIDu pod OS Linux podporuje 5 typy diskových polí:
Historie, dostupnost, omezeníPůvodní ovladač "MetaDisku" (odtud název ovladače - md) napsal Marc Zyngier. Implementace zpočátku delší dobu podporovala pouze typy linear, RAID 0 a RAID 1. Později ovladač vyvíjeli zejména Ingo Molnár, Gadi Oxman a nyní Neil Brown. Přibyla podpora dalších typů polí a podpora bootování z RAIDu 0 a 1. V současné době se můžeme setkat se dvěma verzemi ovladače: verzí 0.42, kterou obsahují čistá jádra řady 2.2.x a verzí 0.90, která se nachází v jádrech řady 2.4.x. Jádra 2.2.x většiny distribucí ale obsahují podporu RAIDu verze 0.90, ovladač této verze pro jádra 2.2.x je k dispozici ve formě záplaty jádra. K provozování softwarového RAIDu je zapotřebí kromě jaderného ovladače také sada utilit raidtools (dříve mdtools), které musejí odpovídat verzi jaderného ovladače (raidtools 0.42 a raidtools 0.90).Ovladače RAIDu jsou testovány především na platformě x86, ale lze je provozovat i na platformách Sun či Alpha (a možná i dalších, ovšem na těchto exotičtějších platformách jsou méně odladěny). Pro jádra řady 2.2.x platí určitá omezení, která vyplývají z architektury této řady jader:
Pro jádra řady 2.4 tato omezení neplatí.
KonfiguraceKonfigurace RAIDu verze 0.90 používá konfigurační soubor /etc/raidtab (na rozdíl od verze 0.42, kde byla konfigurace uložena v /etc/mdtab), ve kterém se používají následující direktivy:
Starší verze softwarového RAIDu (0.40 až 0.51) používaly konfigurační soubor /etc/mdtab. Přestože tato starší verze ovladače je součástí "čistých jader" 2.2.x, je zastaralá a nebudeme se jí zde vůbec zabývat. Pro úplnost je starší verze RAIDu dokumentovaná v příslušném HOWTO.
Příklady konfiguracíPříklad konfigurace pole linear. Mějme pole typu linear složené ze dvou oddílů:
raiddev /dev/md0 raid-level -1 persistent-superblock 1 nr-raid-disks 2 nr-spare-disks 0 device /dev/sda1 raid-disk 0 device /dev/sdb1 raid-disk 1 Příklad konfigurace RAID 0. Mějme diskové pole RAID 0 složené ze dvou oddílů, sda1 a sdb1, velikost stripu je 16 kB:
raiddev /dev/md0 raid-level 0 persistent-superblock 1 chunk-size 16 nr-raid-disks 2 nr-spare-disks 0 device /dev/sda1 raid-disk 0 device /dev/sdb1 raid-disk 1 Příklad konfigurace RAID 1. Mějme diskové pole RAID 1 složené ze dvou oddílů a s jedním rezervním oddílem:
raiddev /dev/md1 raid-level 1 nr-raid-disks 2 nr-spare-disks 1 device /dev/sda1 raid-disk 0 device /dev/sdb1 raid-disk 1 device /dev/sdc1 spare-disk 0 Příklad konfigurace pole RAID 5 s rozložením parity "left-symmetric", velikostí stripu 4 kB a jedním rezervním oddílem:
raiddev /dev/md2 raid-level 5 nr-raid-disks 3 chunk-size 4 parity-algorithm left-symmetric nr-spare-disks 1 device /dev/sda1 raid-disk 0 device /dev/sdb1 raid-disk 1 device /dev/sdc1 raid-disk 2 device /dev/sdc1 spare-disk 0
Obslužný software - RaidtoolsBalíček raidtools (nahrazuje starší balíček mdtools určený pro starší verze ovladače RAIDu) obsahuje obslužné utility nezbytné k manipulaci s diskovými poli:
V budoucnu zřejmě budou utility z balíčku raidtools nahrazeny jedinou utilitou mdctl, kterou vyvíjí Neil Brown. První verze této utility jsou již k dispozici. Utilita mdctl nemusí používat žádný konfigurační soubor, vše potřebné lze zadat na příkazové řádce, anebo to mdctl zjistí analýzou RAID superbloků uložených na discích (podobně funguje automatické startování polí jádrem při bootu). Cílem autora je tedy přidat výhody a robustnost, kterou poskytuje vlastnost raid autodetect jádra a zárověň se vyhnout potenciálním konfliktům mezi neaktuální konfigurací v souboru raidtab a skutečnou konfigurací polí, ke kterým časem může dojít, pokud používáme raidtools. Zatím je utilita mdctl ve stavu vývoje, takže její ostré použití ještě nelze doporučit. Poznámka na vysvětlenou: Soubor raidtab odráží konfiguraci polí v době jejich sestavení, ovšem pokud třeba později vyměníme nebo přesuneme některé disky, nemusí již odrážet skutečnou konfiguraci. Pokud tedy z nějakého důvodu potřebujeme pole znovu inicializovat anebo ho jen startujeme pomocí raidstart, nesmíme zapomenout soubor raidtab ručně upravit, abychom se ušetřili v budoucnu nepříjemností.
Inicializace políJakmile máme odpovídajícím způsobem rozdělené disky a připravený konfigurační soubor /etc/raidtab, můžeme pole inicializovat utilitou mkraid, která pole sestaví a aktivuje. Pokud zakládáme pole s perzistentními RAID superbloky (viz níže), pak mkraid vypíše i pozici RAID superbloků:
# mkraid /dev/md5 handling MD device /dev/md5 analyzing super-block disk 0: /dev/sda7, 20163568kB, raid superblock at 20163456kB disk 1: /dev/sdb7, 20163568kB, raid superblock at 20163456kB Po úspěšné inicializaci bychom měli v souboru /proc/mdstat, který obsahuje informace a aktivních polích vidět odpovídající záznam, např:
$ cat /proc/mdstat Personalities : [raid0] [raid1] [raid5] read_ahead 1024 sectors md0 : active raid1 sdb1[1] sda1[0] 131968 blocks [2/2] [UU] Poté nám nic nebrání pole zformátovat např. pomocí mke2fs, pokud chceme na poli provozovat souborový systém ext2. Utilita mke2fs akceptuje volbu -R stride=X, která udává kolik bloků souborového systému obsahuje 1 "stripe" pole. Tím pádem je také vhodné zadat ručně velikost bloku (parametr -b). Např. mějme pole typu RAID 0 s velikostí stripu 16 kB. Pokud budeme chtít použít velikost bloku souborového systému 4 kB, zadáme:
mke2fs /dev/md0 -b 4096 -R stride=4
Raid autodetect anebo raidstart?Nyní tedy máme funkční diskové pole. Zbývá vyřešit způsob, jakým se bude pole vypínat při vypnutí systému a zapínat při startu systému. Jednou možností je použití utilit raidstart a raidstop. Pomocí těchto utilit můžeme pole aktivovat či zastavit kdykoliv, stačí tedy upravit příslušné startovací skripty. (Pokud už distribuce toto neobsahuje; např. distribuce Red Hat není potřeba upravovat, ze skriptu /etc/rc.d/rc.sysinit je raidstart volán automaticky, existuje-li soubor /etc/raidtab a raidstop je volán ze skriptu /etc/rc.d/init.d/halt.).
Druhou, robustnější metodou je využití možnosti automatické aktivace polí jádrem při bootu. Aby mohla fungovat, je potřeba v prvé řadě používat perzistentní RAID superbloky a všechny diskové oddíly, které jsou součástí polí, musejí být v tabulce oddílů označeny jako typ Linux raid autodetect (tedy hodnota 0xfd hexadecimálně). Viz výpis fdisku - nastavení diskových oddílů pro autodetekci RAID polí. Výhodou tohoto řešení navíc je, že jakmile je diskové pole inicializováno, nepoužívá se již pro opětovný start / zastavení pole konfigurační soubor /etc/raidtab. O sestavení a spuštění pole se postará ovladač RAIDu, který na všech diskových oddílech typu Linux raid autodetect vyhledá RAID superbloky a na základě informací v RAID superblocích pole spustí. Stejně tak ovladač RAIDu všechny pole korektně vypne v závěrečné fázi ukončení běhu systému poté, co jsou odpojeny souborové systémy. I v případě změny jmen disků nebo po přenesení disků na úplně jiný systém tedy pole bude korektně sestaveno a nastartováno, viz následující úryvek systémového logu po zámeně disků sdc za sdb a sdb za sda:
autorun ... considering sdb6 ... adding sdb6 ... adding sda6 ... created md4 bind<sda6,1> bind<sdb6,2> running: <sdb6><sda6> now! sdb6's event counter: 00000001 sda6's event counter: 00000001 md: device name has changed from sdc6 to sdb6 since last import! md: device name has changed from sdb6 to sda6 since last import! md4: max total readahead window set to 128k raid1: device sdb6 operational as mirror 1 raid1: device sda6 operational as mirror 0 md: updating md4 RAID superblock on device sdb6 [events: 00000002](write) sdb6's sb offset: 15332224 sda6 [events: 00000002](write) sda6's sb offset: 15332224
RAID superblokKaždý diskový oddíl, který je součásti raid svazku (výjimku tvoří pouze svazky bez perzistentních superbloků, viz níže) obsahuje tzv. RAID superblok. Tento superblok je 4kB část RAID oddílu vyhrazená pro informace o příslušnosti daného oddílu k určitému poli a o stavu pole. Následuje podrobný popis superbloku, který se nám bude později hodit při řešení některých problémových situcací popsaných níže. Čtenář, který se nechce RAIDem zabývat do hloubky, může tuto část přeskočit.
RAID superblok (o velikosti 4 kB) je uložen na konci diskového oddílu. Jeho pozici získáme buď ze systémového logu (ovladač RAIDu loguje updaty RAID superbloku):
md: updating md0 RAID superblock on device kernel: sdb1 [events: 000000e8](write) sdb1's sb offset: 8956096 nebo ji také můžeme odvodit z velikosti diskového oddílu (komentář zdrojového kódu balíčku raidutils):
If x is the real device size in bytes, we return an apparent size of: y = (x & (MD_RESERVED_BYTES - 1)) - MD_RESERVED_BYTES and place the 4kB superblock at offset y. #define MD_RESERVED_BYTES (64 * 1024) Nejjednodušší je ale podívat se do /proc/mdstat, kde je uvedena velikost každého svazku v blocích, např. u pole typu RAID 1:
md0 : active raid1 sdb1[1] sda1[0] 131968 blocks [2/2] [UU]
RAID superblok z diskového oddílu sdb1 pak získáme a uložíme do souboru /tmp/superblok příkazem:
dd if=/dev/sdb1 of=/tmp/superblok bs=1k skip=131968 count=4 Jestliže se jedná o pole RAID 0, složené ze dvou disků, pak velikost získanou z /proc/mdstat vydělíme 2 např:
md4 : active raid0 sdd1[1] sdc1[0] 17942272 blocks 16k chunks pak superblok zkopírujeme příkazem:
dd if=/dev/sdb1 of=/tmp/superblok bs=1k skip=8971136 count=4 Prohlédnout si jej můžeme např. pomocí utility od (s vhodnými parametry, např. od -Ax -tx4). Pro kontrolu, superblok vždy začíná "magickým číslem" 0xa92b4efc. Superblok obsahuje zejména následující informace:
Perzistentní superbloky a RAID 0 / linearPokud provozujeme pole RAID 0 či linear, máme možnost zvolit variantu bez použití perzistentního superbloku. Volba "persistent-superblock 0", znamená, že se RAID superblok nebude ukládat na disk. Tato možnost existuje z důvodů zachování kompatibility s polemi zřízenými pomocí starší verzí ovladače RAIDu. Po vypnutí takového pole nezůstane na svazku informace o konfiguraci a stavu pole. Proto je tato pole nutné vždy znovu inicializovat při každém startu buď utilitou mkraid, nebo pomocí utility raid0run (což je pouze symbolický odkaz na mkraid) a nelze využít automatického startování polí jádrem při bootu.Poznámka: Na tuto volbu je třeba dávat pozor při konfiguraci - pokud při konfiguraci pole RAID 0 direktivu persistent-superblock vynecháme, použije se standardní hodnota 0, tedy pole bez perzistentních superbloků!
Monitorování stavu poleAktuální stav diskových polí zjistíme vypsáním souboru /proc/mdstat. První řádek obsahuje typy polí, které ovladač podporuje (záleží na konfiguraci jádra). U jednotlivých RAID svazků je pak uvedeno které diskové oddíly svazek obsahuje, velikost svazku, u redundantních polí pak celkový počet konfigurovaných oddílů a z toho počet funkčních, následovaný schématem funkčnosti v hranatých závorkách. Následující příklad uvádí stav funkčního pole RAID 1:
md0 : active raid1 hdc1[1] hda1[0] 136448 blocks [2/2] [UU] Druhý příklad uvádí stav pole RAID 1 po výpadku jednoho disku, oddíl sdc1 je označen jako nefunkční (F=Failed místo čísla aktivního oddílu):
md0 : active raid1 sdc1[F] sdd1[0] 8956096 blocks [2/1] [U_] Třetí příklad ukazuje stav pole RAID 1, kdy probíhá rekonstrukce:
md1 : active raid1 hdc2[1] hda2[0] 530048 blocks [2/2] [UU] \ resync=4% finish=6.7min Součástí raidtools bohužel není utilita k monitorování stavu diskových polí, takže si administrátor musí vypomoci skriptem, který je pravidelně spouštěn z cronu a kontroluje /proc/mdstat (jednoduše např. tak, že si skript na disk uloží obsah /proc/mdstat nebo jeho MD5 součet a následně kontroluje, jestli se /proc/mdstat změnil; v případě změny pak prostřednictvím e-mailu uvědomí administrátora) anebo filtrem systémového logu.
Rekonstrukce poleRedundantní typy polí je třeba po inicializaci, po výměně disku, nebo po nahrazení vadného disku rezervním (viz direktiva spare-disk v /etc/raidtab) rekonstruovat či synchronizovat. Ve všech případech systém rekonstrukci spouští automaticky. Průběh rekonstrukce je možné sledovat v /proc/mdstat (viz příklad o několik řádek výše). Rekonstrukce probíhá s nízkou prioritou, nezabere tedy čas procesoru na úkor jiných aplikací, ale bude se snažit využít maximální prostupnosti I/O zařízení. Proto můžeme po dobu rekonstrukce pozorovat zpomalení diskových operací. Maximální rychlost rekonstrukce ovšem také lze ovlivnit nastavením limitu v /proc/sys/dev/md/speed-limit, výchozí hodnota je 100 kB/sec. Ovladač RAIDu umí současně spustit rekonstrukci na několika polích současně. Pokud jsou však oddíly jednoho disku součástí více polí, které by se měly synchronizovat současně, provede se synchronizace polí postupně (z důvodu výkonu). V systémovém logu se pak objeví neškodné hlášení typu "XX has overlapping physical units with YY":
md: syncing RAID array md1 md: minimum _guaranteed_ reconstruction speed: 100 KB/sec. md: using maximum available idle IO bandwith for reconstruction. md: using 128k window. md: serializing resync, md2 has overlapping physical units with md1! md: md1: sync done. md: syncing RAID array md2 md: minimum _guaranteed_ reconstruction speed: 100 KB/sec. md: using maximum available idle IO bandwith for reconstruction. md: using 128k window. md: md2: sync done. V /proc/mdstat jsou ty svazky, na kterých je rekonstrukce pozastavena, označeny jako plně funkční, ale je u nich poznámka resync=DELAYED:
Personalities : [linear] [raid0] [raid1] [raid5] read_ahead 1024 sectors md2 : active raid1 hdc3[1] hda3[0] 530048\ blocks [2/2] [UU] resync=DELAYED md1 : active raid1 hdc2[1] hda2[0] 530048\ blocks [2/2] [UU] resync=4% finish=6.7min md0 : active raid1 hdc1[1] hda1[0] 136448\ blocks [2/2] [UU] Pokud zformátujeme a připojíme čerstvě zřízené redundantní pole, na kterém probíhá rekonstrukce, mohou se v systémovém logu objevit následující neškodné hlášení (je to způsobené tím, že mke2fs, fsck a ovladač FS používají při přístupu jinou velikost bloku, než je výchozí velikost se kterou pracuje ovladač raidu):
kernel: set_blocksize: b_count 1, dev md(9,3),\ block 96765, from c014 kernel: set_blocksize: b_count 1, dev md(9,3),\ block 96766, from c014 kernel: set_blocksize: b_count 2, dev md(9,3),\ block 96767, from c014 kernel: md3: blocksize changed during write kernel: nr_blocks changed to 32 (blocksize 4096,\ j 24160, max_blocks 385536)
Redundantní pole: výměna disku, hot plugPokud při čtení nebo zápisu na některý z diskových oddílů, který je součástí redundantního diskového pole, dojde k chybě, je dotyčný oddíl označen jako vadný a pole jej přestane používat. Pokud máme v daném diskovém poli zařazen jeden nebo více rezervních disků (direktiva spare-disk), je tento v případě výpadku automaticky aktivován, systém provede rekonstrukci pole a průběh rekonstrukce zaznamená do systémového logu. V opačném případě pole zůstane v provozu v degradovaném režimu, pak to v systémovém logu bude vypadat zhruba takto:
kernel: SCSI disk error : host 0 channel 0\ id 4 lun 0 return code = 28000002 kernel: [valid=0] Info fld=0x0, Current sd08:11:\ sense key Hardware Error kernel: Additional sense indicates\ Internal target failure kernel: scsidisk I/O error:\ dev 08:11, sector 2625928 kernel: raid1: Disk failure on sdb1,\ disabling device. kernel: Operation continuing on 1 devices kernel: md: recovery thread got woken up ... kernel: md0: no spare disk to reconstruct\ array! - continuing in degraded mode kernel: md: recovery thread finished ... Příjemnou vlastností diskových polí je také možnost výměny disku za chodu systému. Samozřejmě k tomu potřebujeme v prvé řadě hardware, který to umožňuje. Ovladače slušných SCSI řadičů umožňují přidávání či ubírání zařízení, to ale samo o sobě nestačí. Je zapotřebí používat SCA disky určené pro "hot swap" a odpovídající SCSI subsystém s SCA konektory a elektronikou, která zajistí stabilitu SCSI sběrnice při odebírání či přidávání zařízení. Mějme pole typu RAID 1, ve kterém došlo k chybě na oddílu sdc1. Disk sdc1 je připojen ke kanálu 0 SCSI řadiče 0 a má ID rovno 4:
md0 : active raid1 sdc1[F] sdd1[0] 8956096 blocks [2/1] [U_] Jak tedy probíhá výměna vadného disku, máme-li k tomu potřebné hardwarové vybavení:
Pokud nemáme hardware potřebný k "hot-swap" výměně disků, musíme se smířit s vypnutím systému, výměnou vadného disku a opětovným zapnutím systému. Potom stačí pouze vytvořit pomocí fdisku odpovídající diskové oddíly a příkazem raidhotadd je zařadit do diskového pole. Příkazy pro přidávaní a ubírání SCSI zařízení jsou popsány ve zdrojovém kódu jádra (soubor linux/drivers/scsi/scsi.c).
IDE nebo SCSI?Doposud jsme se zbývali obecně fungováním softwarového RAIDu, ovšem ve chvíli kdy se rozhodneme sestavit systém s RAIDem, musíme se zamyslet nad výhodami a nevýhodami těchto rozhraní, které s provozováním diskových polí souvisejí. Protože tato problematika je sama o sobě rozsáhlá, uvedeme na tomto místě pouze několik zásadních rozdílů:Rozhraní SCSI má několik rysů, které napomáhají vyššímu výkonu diskového subsystému:
Rozhraní IDE má naopak několik nedostatků, které komplikují jeho nasazení, zejména:
Je tedy jasné, že ačkoliv maximální teoretické propustnosti obou rozhraní jsou dnes poměrně vysoké, v prostředí, kde je kladen důraz na reálnou vysokou propustnost nejen při sekvenčním čtení nebo zápisu, je rozhraní SCSI stále volbou číslo jedna. Pokud se rozhodneme budovat systém na bázi IDE, rozhodně se vyplatí obsazovat každý kanál IDE pouze jedním zařízením. (A to jak z důvodu výkonu, tak stability, protože pokud bychom např. sestavili pole RAID 5 z IDE disků a disky by byly na kanálech po dvou, riskujeme v případě výpadku některého z "master" disků havárii celého pole, protože tím mohou v krajním případě vypadnout disky oba - jak "master" tak i "slave"".)
TestováníKdyž zprovozníme redundantní diskové pole, bude nás zajímat i způsob, jakým otestovat jeho odolnost proti výpadku disku. Můžeme k tomu použít utilitu raidsetfaulty, která simuluje výpadek disku a označí jej jako vadný (je potřeba mít dostatečně novou verzi balíčku raidtools, ve starších verzích tatu utilita chybí). Potom můžeme disk vyřadit z pole příkazem raidhotremove, opět přidat příkazem raidhotadd a sledovat průběh rekonstrukce pole. Metodu testování tím, že za chodu vytáhneme konektor disku, rozhodně nelze doporučit, protože tímto způsobem můžeme hardware vážně poškodit.
TipyNyní už máme za sebou jak teorii fungování RAIDu, tak z velké části i praxi softwarového RAIDu pod Linuxem. V této poslední části se zaměříme na méně obvyklé postupy a tipy, jak řešit některé problémové situace.
Jak založit redundantní pole v degradovaném režimuSoftwarový RAID je poměrně flexibilní. Pokud jsme například v situaci, kdy potřebujeme převést systém běžící na samostatném disku na redundantní pole RAID 1, nemusíme kvůli tomu reinstalovat systém. Můžeme využít toho, že lze vytvořit pole v degradovaném režimu. Dejme tomu, že máme instalovaný systém na diskovém oddílu sda1 a pro zjednodušení je to jediný oddíl na disku sda. Do počítače jsme přidali disk stejně velký disk sdb a máme připraveno jádro podporující sofwarový RAID. Pomocí fdisku vytvoříme diskový oddíl sdb1 obdobně jako je na disku sda. Nyní vytvoříme konfigurační soubor /etc/raidtab:
raiddev /dev/md0 raid-level 1 persistent-superblock 1 nr-raid-disks 2 nr-spare-disks 0 device /dev/sdb1 raid-disk 0 device /dev/sda1 failed-disk 1 Pomocí mkraid inicializujeme pole, vytvoříme na něm souborový systém (např. pomocí mke2fs), přípojíme a zkopírujeme na něj data z sda1. Odpovídajícím způsobem upravíme konfigurační soubory na svazku md0 (/etc/fstab apod.). Po té systém nabootujeme ze svazku md0 (třeba pomocí diskety anebo upravíme konfiguraci pro LILO), zkontrolujeme, že je vše v pořádku a příkazem raidhotadd přidáme oddíl sda1 do pole.
Jak přidat třetí aktivní disk do pole RAID 1Pokud máme pole RAID 1 tvořené dvěma disky a rozhodneme se pro zvýšení redundance přidat ještě třetí, nestačí na to pouze příkaz raidhotadd. Ten totiž disk do pole přidá, ale pouze jako disk rezervní ("spare"). Pokud chceme, aby byl třetí disk také aktivní, musíme si opět pomoci direktivou failed-disk v konfiguračním souboru /etc/raidtab. Třetí disk označíme jako failed-disk a nezapomeneme zvýšit celkový počet aktivních disků na 3 (nr-raid-disk):
raiddev /dev/md0 raid-level 1 persistent-superblock 1 nr-raid-disks 3 nr-spare-disks 0 device /dev/sda1 raid-disk 0 device /dev/sdb1 raidd-disk device /dev/sdc1 failed-disk Poté pomocí mkraid pole znovu inicializujeme a příkazem raidhotadd přidáme oddíl sdc1. (Tím, že označíme nový disk jako failed-disk zajistíme, že jej mkraid při inicializaci přeskočí, ale pole bude počítat se 3 disky, následné spuštění raidhotadd pak zajistí aktivaci.)
Když z RAIDu 5 vypadne více diskůRAID 5 je odolný vůči výpadku jednoho disku. Protože se stripuje, nejsou data z jednotlivých disků samostatně použitelná a tato situace je téměř neřešitelná. Co tedy dělat v případě, když k výpadku více než jednoho disku dojde? Pokud disky zůstaly po výpadku pole alespoň částečně použitelné, můžeme se pokusit o obnovení pole následujícím způsobem, opět s využitím direktivy failed-disk. Utilita mkraid v podstatě pouze zapíše na oddíly RAID svazku superbloky a nastartuje pole - nijak tedy nemění obsah oddílů. Teprve jaderný ovladač RAIDu spouští rekonstrukci a tomu můžeme zabránit tím, že pomocí mkraid pole znovu inicializujeme, ale pouze v degradovaném režimu (upravíme raidtab). Pole pak můžeme připojit s příznakem pouze pro čtení a zjistit, nakolik jsou data na svazku použitelná. Toto můžeme podle potřeby opakovat a postupně z pole vynechat jiný z disků, které z pole v době havárie vypadly, až najdeme takovou kombinaci, při které je souborový systém poškozen nejméně (můžeme zkusit spustit fsck). Potom můžeme svazek připojit i pro zápis a pomocí fsck souborový systém naostro opravit. Na závěr můžeme přidat i poslední chybějící disk pomocí raidhotadd, což vede ke spuštění rekonstrukce pole. Tato metoda ale představuje krajní řešení a rozhodně od ní nelze očekávat zázraky.
Když se změní pořadí či jména diskůPokud se změní pořadí nebo jména zařízení (např. přidání dalších disků či periferií), které tvoří RAID svazek a nepoužíváme automatické startování RAIDu jádrem při bootu, musíme odpovídajícím způsobem upravit konfigurační soubor /etc/raidtab a případně pole znovu inicializovat pomocí mkraid -force (pozor - pouze pro ty, kteří vědí, co dělají). Pokud používáme vlastnost "raid autodetect" jádra, ovladač RAIDu si poradí sám a pole sestaví a spustí podle informací uložených v RAID superblocích diskových oddílů.
Rozšíření pole, konverze raidu na jiný typUtilita raidreconf, kterou původně vyvíjel Jakob Oestergaard, nyní vyvíjená jako open source aktivita Connexem, umí zmenšovat, zvětšovat RAID 0 a 5 svazky, převádět svazky typu RAID 0 na RAID 5, přidat nový disk do RAIDu 1 a 5, vytvořit pole RAID 0 ze samostatných disků. Tato utilita ale není dostatečně testována, takže pozorné čtení manuálu a záloha je naprostou nutností! Spolu s utilitou resize2fs je tedy možné tedy možné měnit i velikost polí.
Boot raidJe možné provozovat kořenový svazek na RAIDu, a to typu linear, RAID 0 a RAID 1. Konfigurace starších verzí LILa byla sice trochu problematická, ale nové verze LILa již RAID podporují přímo, viz Software-RAID-0.4x-HOWTO (ke starší verzi RAIDu), Boot+Root+Raid+LILO HOWTO (k nové verzi RAIDu).
Jak potlačit autodetekci RAID políPokud máme jádro s podporou autodetekce RAID polí a z nějakého důvodu potřebujeme autodetekci dočasně vypnout, můžeme jádru při startu zadat parametr raid=noautodetect.
RAID a swapV souvislosti s RAIDem se často diskutuje o tom, zda má smysl vytvářet odkládací oddíly na RAIDu a když ano, tak jaký typ pole použít. Tady je zapotřebí vzít v potaz omezení daná ovladačem RAIDu (viz výše omezení platná pro jádra 2.2.x) a dále se musíme rozhodnout, zda nám jde o zrychlení swapování, nebo o robustnost systému. Pokud nám jde o rychlost, můžeme jako odkládací oddíl použít svazek RAID 0; ovšem podobného efektu můžeme dosáhnout i bez použití RAIDu a to tak, že v /etc/fstab uvedeme u odkládacích oddílů stejnou prioritu:
/dev/sda3 none swap sw,pri=1 /dev/sdb3 none swap sw,pri=1 Používat pro swap RAID 0 je tedy v podstatě zbytečné. Naopak v případě, že nám jde o robustnost systému, můžeme pro odkládací oddíl s výhodou použít RAID 1 svazek. Systém pak s výpadkem disku nepřijde o část swapu.
Výkon a stabilitaNejprve srovnejme výkon softwarového raidu pod jádry 2.2 a 2.4: RAID 0 je rychlejší u jader 2.4, RAID 1 je na tom zhruba stejně, RAID 5 byl na řadě 2.4 z počátku výrazně pomalejší, i když toto se v poslední době rychle mění a nyní je výkon srovnatelný nebo lepší. Pokud jde o srovnání rychlosti softwarového RAIDu a hardwarových řešení, softwarový RAID je oproti hardwarové implementaci samozřejmě náročnější na systémové prostředky, ale na druhou stranu bývá mnohdy rychlejší (výrazně rychlejší bývá zejména RAID 0). (Poznámka: pro vylepšení výkonu RAIDu 1 při čtení existuje záplata ovladače RAIDu "readbalance".)Pokud jde o robustnost implementace, stabilita RAIDu typů linear, RAID 0 a 1 je poměrně vysoká, naopak nasazení RAIDu 5 v ostrém provozu ještě nelze doporučit. V této souvislosti ještě zmíním jednu vlastnost Linuxové implementace softwarového RAIDu: V případě jakékoliv I/O chyby ovladač RAIDu okamžitě daný diskový oddíl z RAIDu vyřadí, bez ohledu na to, jestli se jedná o chybu fatální, anebo o případ, kdy by třeba stačilo danou I/O operaci zopakovat. Jinými slovy disk, který občas vrátí nějakou chybu, ale je nadále více méně schopný fungovat (a který by systém nadále používal, pokud by nebyl součástí RAID svazku, ale byl připojený jako samostatný oddíl), linuxový ovladač přestane používat. Tím se zbytečně snižuje robustnost RAIDu, protože snadněji může dojít k situaci, kdy z pole vypadne postupně i více disků, než kolik je k provozu daného pole třeba a pole zhavaruje. Proto lze doporučit použití rezervních disků a vyhnout se shánění rezervního disku na poslední chvíli, kdy už pole mezitím běží v degradovaném režimu. Ze srovnání softwarových RAID implementací Linuxu, Windows 2000 a Solarisu vyplývá, že linuxový RAID ve výchozím nastavení provádí rekonstrukci se sníženou prioritou a limitovanou rychlostí, takže probíhající rekonstrukce mnohem méně negativně ovlivňuje výkon systému po dobu rekonstrukce. (Poznámka: V odkazovaném srovnání ovšem autoři opakovaně chybně uvádějí absenci některých vlastností linuxové softwarové implementace RAIDu.)
ZávěremSoftwarový RAID je cenově lákavou alternativou nákladných hardwarových řešení. Další výhodou je flexibilita (např. možnost sestavení pole v degradovaném režimu, možnost eventuální částečné záchrany dat v případě výpadku celého pole, protože je známá struktura dat v diskovém poli, konverze RAID svazků z jednoho typu RAIDu na jiný). Některé z těchto možností jsou ale spíše experimentálního rázu. Za spolehlivé lze označit implementace RAIDu typu linear, RAID 0 nebo RAID 1. Softwarový RAID je náročnější na systémové prostředky než hardwarová řešení, některé typy (zejména RAID 0) ovšem mohou být výrazně rychlejší než hardwarové varianty. Je tedy na adminstrátorovi, aby zvážil výhody a nevýhody sofwarového či hardwarového RAIDu vzhledem k aktuálním podmínkám.
Tento článek ani v nejmenším nenahrazuje dokumentaci k ovladači Linuxového
softwarového RAIDu či obslužným utilitám - proto zde až na výjimky záměrně
nejsou komentovány přepínače obslužných utilit. Důkladné čtení dokumentace
(nebo v případě nejasností studium zdrojového kódu - dokumentace bohužel
stále není úplná) by mělo být samozřejmostí, rovněž existuje konference
linux-raid s prohledávatelným
archívem.
A ještě úplně poslední poznámka na závěr:
nezapomínejme, že (redundantní) RAID chrání pouze před výpadkem určitého
počtu disků a rozhodně nenahrazuje nutnost pravidelného zálohování dat.
|
|||